Introduction
머신러닝과 딥러닝의 등장으로 많은 문제들이 해결되며 인공지능 기술의 가능성을, 그리고 그 가능성이 현실에서 충분히 적용될 수 있음을 확인하고 있다. 이러한 딥러닝 혹은 머신러닝 등의 성능을 높이고, 복잡하고 어려운 문제들에 적용하기 위해서 모델의 크기가 점점 커지고 있고, 뿐만 아니라 사용자들에게 뿌려져 있는 스마트폰과 같은 컴퓨팅 리소스를 활용하여서 학습을 하는 등 다양한, 새로운 접근을 하고 있다.
대부분의 딥러닝 모델들은 back-propagation을 기반으로 학습을 하며 그 과정에서 gradient를 계산한다. 이렇게 gradient 정보가 학습에 기반이 되다보니 여러 device나 server에서 학습을 하는 distributed learning이나 federated learning에서는 이 gradient 정보를 교환하는 경우가 많다. 기본적으로 gradient 정보는 학습된 모델의 parameter에 대한 직접적인 정보를 공유하지 않으니 model의 정보 자체를 유출하지도 않고 학습 데이터에 대한 정보량이 사실상 없다고 봐왔기 때문에 gradient는 privacy의 측면에서 매우 적절한 정보라고 생각해왔다.

그런데 이 논문에서는 사실 gradient 정보를 통해서 학습에 활용된 데이터를 매우 높은 퀄리티로 복원할 수 있다는 것을 보였다. 위 그림에서는 두 가지 distributed learning scenario를 보여주는데 그냥 gradient가 공유되는 시점에서 gradient만 얻을 수 있으면 학습에 활용된 정보를 얻을 수 있다는 것을 보여주는 것이다.
논문에서는 이렇게 gradient에서 training 정보를 얻어내는 전체 파이프라인을 Deep Leakage from Gradient (DLG)라고 이름을 지었다. 해당 논문의 contribution은 다음과 같다.
- Gradient로부터 training에 사용된 private data를 얻을 수 있다는 것을 최초로 보인 연구이다.
- Gradient만 가지고 이미지는 pixel 수준, 자연어는 token 수준으로 알아낼 수 있다. 다른 방식들은 추가적인 정보도 필요하고 그정도 퀄리티로 복원할 수 없다.
- Attack만 제안하는 것이 아니라 어떻게 defense 할지도 제안한다.
논문의 Related Work에서는 해당 attack이 일어나는 distributed learning 상황에 대한 내용과 gradient를 기반으로 학습 데이터를 추출하려는 기존 연구들을 소개하는데, 이를 이 게시물에서 구체적으로 다루지는 않겠다. 그냥 단순히 1) distributed learning에서는 gradient를 share한다 2) 기존의 연구들이 제안하는 방식으로는 부족하다. 정도로 요약하련다.
Method
구체적인 방법을 논의하기 전에 저자들은 gradient가 무엇인지, 어떻게 모델이 학습되는지에 대해서 이야기 한다.
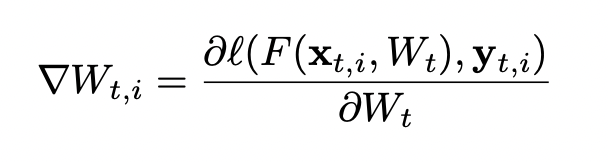
수식을 간단히 설명하면 어떤 시점 $t$에서 $i$번째 학습 데이터 $x_{t, i}$와 그 데이터의 label $y_{t, i}$를 $W_{t}$라는 parameter를 가진 모델 $F()$에 대해 계산한 loss를 기반으로 gradient를 계산하는, 흔히 이야기하는 deep learning에서의 gradient 계산이라고 할 수 있다.

결국 gradient들은 기본적으로 각 데이터별로 계산이 되는데, 결국 모델을 모든 데이터에 대해서 학습하기 위해서 계산된 gradient를 평균내고, learning rate ($=\eta$)를 곱해서 $t+1$ 시점의 weight $W_{t+1}$을 계산한다. 기본적인 deep learning이 기본적으로 다루는 gradient 기반 model update 과정이다.

위 그림은 attack이 일어나는 상황을 나타낸 그림이다. Differentiable Model이라는 단어가 나오는데 이는 gradient를 기반으로 학습되는 모델이어야 하니 미분 가능한 모델이어야 한다는 소리다. 아무튼 위의 Normal Participant는 정상적으로 학습을 하는 유저로 앞서 이야기한 방식으로 gradient를 계산하고 이러한 정보가 어떠한 이유로든 노출되고 attacker가 이를 얻은 상황이라면 attacker는 이 gradient를 기반으로 입력을 재건하려 시도한다. 구체적인 방식은 다음과 같다.

우선 attacker는 victim과 동일한 parameter를 가지는 model을 가지고 있다고 가정한다. 우선 gaussian distribution을 따르는 noise를 입력과 label로 initialize해준다. 이제 이 noise를 기반으로 계산한 gradient가 Victim이 계산한 gradient와 가까워지도록 입력과 레이블을 최적화 한다 (model weight $W$는 고정되어 있음).


결국 이야기 하는 것은 어떤 weight를 가지는 model이 있고 해당 weight에서 특정 gradient를 생성하는 입력과 label을 알아낼 수 있다는 것이다. 계산하는 방식 자체는 그냥 계산되는 gradient가 유사해지도록 하는 $x'$와 $y'$를 찾는 것. loss는 단순히 두 gradient의 차이의 제곱을 활용했다.
Experiments

뭐 별거 없다. Iteration이 진행되며 training에 사용되는 data를 거의 완벽하게 복원해내는 모습이다. 뭔가 noise로부터 image가 나오는 모습이 diffusion model 같기도 하고 신기한 모습...

NLP task에서도 매우 우수하게 동작하는 모습을 볼 수 있다...

그런데 학습 과정에서 입력을 하나씩 받으라는 법은 없다. 일반적으로 batch를 기반으로 학습을 하니 batched data를 대상으로 attack을 수행한 경우를 본다. 뭐 순서 자체는 달라질 수 있지만 사용된 입력을 재건하는 것이 가능하다는 것을 잘 보여주는 결과다. (근데 어차피 분산 학습 상황에서는 batch 단위으로 나온 gradient를 평균 때려서 공유하지 않나...? 잘 모르는 분야라 조심스럽다...)
뭐 논문에서 추가적으로 더 많은 실험들도 하고 있지만 게시물에서는 다루지 않겠다. 궁금하신 분은 원문을 읽어보시라
Deep Leakage from Gradients
논문이 좋은 평가를 받았을 수 있었던 것 중 하나는 많은 attack paper들이 attack 방법만 제시하는 경우가 많은데 이 논문은 꽤나 comprehensive하게 defense 관련 실험도 진행했다. 뭐 아이디어 자체가 꽤나 간단해서 attack만 가지고는 논문을 풍부하게 구성하기 어려운 것도 있었을 것 같고, attack이든 defense든 그 한계를 명확하게 보여주는 것이 좋다고 생각한다.
논문에서는 3가지 defense strategy를 소개한다. 1) gradient에 노이즈 섞기 2) precision 낮추기 3) gradient pruning가 바로 그것이다. 결국 학습 과정에서 gradient의 정보량을 줄여 data가 leak되지 않도록 하는 것이다. 중요한 것은 1) 학습 결과에는 크게 영향을 주지 않아야 함. 2) defense를 확실히 해야 함. 두가지다.
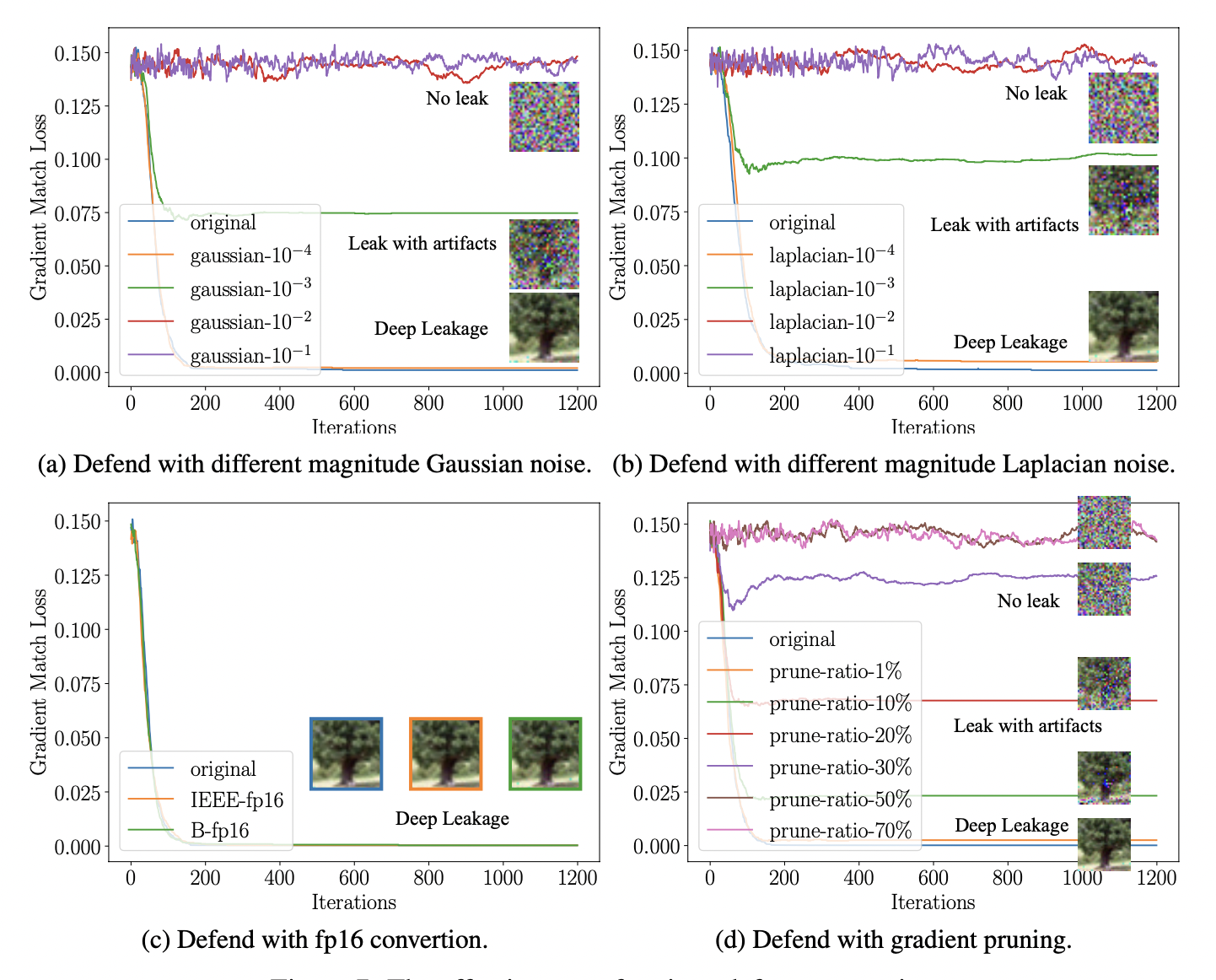
결론은 Precision을 떨어뜨리는 방식을 제외한 두 방식이 모두 defense에 효과적이었다는 것.
Conclusion
논문을 직접 읽어보면 그리 어려운 개념도 없고, 금방 술술 읽히는 편이었다. writing도 친절하고 다루는 주제 자체가 어렵거나 복잡하지 않아서 굉장히 쉽게 읽히는 편인 것 같다. prunning이나 noise injection을 뚫을 만한 attack이 충분히 많을 것 같은데 연구해볼법 한 것 같다. 그리고 외부 attacker가 현재 parameter를 모른다면 어떻게 attack할 수 있을지도 더 알아봐야 할 것 같다.
그리고 논문의 내용을 많이 압축하고 제외한 리뷰이기 때문에 관심있는 분은 직접 논문을 읽어보시는 것을 권장드린다.

