논문 리뷰) (Mobisys 2022) Detecting Counterfeit Liquid Food Products in a Sealed Bottle Using a Smartphone Camera (1)
저번 학기 세미나에서 발표했었던 논문. Mobisys 2022년에 나온 논문이고 실생활과 관련된 논문으로 best-poster도 같이 받은 연구다. Introduction 우리가 평소에 소비하는 술, 꿀, 기름 등 액체로 된 상품
kichanglee.tistory.com
논문의 기본적인 스토리와 high-level 수준에서의 scheme은 이전 게시글에 작성해두었고 해당 게시글에서는 구체적인 시스템의 분석을 합니다.
System Overview

전체적인 시스템의 구조는 위의 그림과 같다. 논문은 크게 두 개의 phase를 가지는데, Bootstrapping phase와 Verification phase로 나뉜다. 쉽게 생각하면 Bootstrapping phase는 레이블이 있는 비디오 데이터셋을 구축하고 liquid content model에 대한 모델을 학습시키는 과정입니다. Verification phase는 이용자의 device에서 video를 촬영하고 preprocessing, feature extraction, 그리고 bootstrapping phase에서 학습된 모델을 가지고 진품 가품 여부를 판별하는 과정을 의미합니다.
Preprocessing
위 그림은 Preprocessing 과정을 디테일하게 나타낸 figure입니다. 내부적으로는 Frame Selection, Pre-screening Test, Frame Processing, Distance Estimation으로 구성되어 있습니다. Preprocessing의 전체적인 목표는 1) camera setting으로부터 발생할 수 있는 challenge들을 해결하고 2) Input video에 존재하는 redundant information을 줄이는 것에 있습니다.
Frame Selection
Frame Selection의 경우 Faster-RCNN이라는 object detection model을 통해 Bubble을 detection하고 비디오에 표시되어 있는 marker를 찾아냅니다. 이 과정에서 bottle marker는 병에 존재하는 라벨과 같이 고정적으로 존재하는 부분을 이야기합니다. 이 부분도 개인적으로는 이전 게시글의 assumption에 들어가야 하는 내용이라고 생각이 되긴 합니다만, 우선 그냥 넘어가도록 합시다.
이 과정에서 최종적으로 얻는 것은 Steady Frame입니다. 선정 기준은 1) bubble이 존재하는 frame, 2) 지나치게 흔들리지 않은 steady한 frame, 3) 그리고 bubble vector가 직선으로 움직이는 frame들 입니다. 선별된 frame 이외의 frame들은 사용되지 않는다고 보시면 될 것 같습니다.
Pre-screening Test
Pre-screening Test 단계는 앞서 선별된 frame들이 Steady frame들이 적절하게 나왔는지를 확인하는 단계입니다. 만약 선별된 frame들이 이후 bubble feature를 추출 단계에 활용되기 적절하지 않다고 판단되는 경우 다시 video를 촬영하도록 합니다.
Frame Processing & Distance Estimation
Frame processing 단계에서는 크게 두 가지의 일을 합니다. 1) Bubble이 존재하는 ROI (Region of Interest)를 crop하기, 2) Bubble이 이동하는 방향 즉 Bubble vector가 vertical axis와 align되도록 rotation하기 입니다. 이를 통해 이후 Bubble feature extraction에 video에서 bubble 정보만 활용하도록 강제할 수 있는 것입니다. 결국 앞서 말한 redundant information을 제거하는 과정으로 보입니다.
Distance estimation의 경우 앞서 얻은 Marker의 정보를 활용합니다. 실제 카메라가 멀리 있으면 물체는 영상에서 작게 나올 것이고 가깝다면 크게 나올 것입니다. 그런데 저희는 bubble이 얼마나 빠르게 이동하는지를 봐야하는 것이니 실제 크기에 대한 정보가 필요합니다. 따라서 marker의 실제 크기와 영상에서의 pixel 크기나 거리에 기반하여 비율 Rref를 구합니다. 차후 이 비율 정보를 통해 실제 physical world에서의 크기를 계산하는데 이용됩니다.
Bubble Feature Extraction
앞선 전처리 과정을 통해 Bubble에 대한 정보가 잘 담긴 Processed Frame들과 Reference Ratio를 얻었으니 이제 Feature를 추출하면 됩니다. Bubble Feature Extraction 단계에서는 Bubble segmentation과 Bubble tracking 2개의 module로 구성됩니다. 해당 단계에서는 bubble feature를 잘 추출하기 위해서 각 frame에서의 bubble의 위치를 파악하고 frame간 bubble의 위치 변화를 통해 속도를 계산하여 논문에서 활용하고자 했던 feature들인 radius, aspect ratio, velocity, V-R ratio를 찾아냅니다(정확히는 점도, 밀도, 표면장력을 찾는 것이지만 strokes' law와 young-laplace law에 따라 위 정보들을 통해 점도, 밀도, 표면장력에 대한 정보를 간접적으로 추론할 수 있게 되는 것입니다).
Bubble Segmentation
우선 해당 단계의 목표는 module의 이름에서 알 수 있듯이 bubble을 segmentation 하는 것입니다. 효과적 그리고 효율적으로 bubble을 찾아내기 위해 frame들의 contrast를 증가시켜 frame을 enhancing합니다. 논문에서는 다음과 같은 수식을 기반으로 constrast increasing을 수행합니다.
cpixel=α⋅cpixel−β
해당 수식에서 α=2, β=200으로 emprical하게 설정했다고 합니다.
Enhancing된 frame은 semantic segmentation에 활용되는 유명한 모델인 U-Net을 통해 segmentation을 수행합니다. 해당 모델의 경우 200장의 bubble image를 통해 학습시켰다고 합니다. 사실 200장이 그렇게 많은 데이터의 개수는 아니지만, class가 매우 많은 상황도 아니고 bubble의 유무만 찾으면 되는 task이기 때문에 데이터셋 레이블링만 조금 고생해서 해놓는다면 충분히 가능한 task 같습니다.
이후 Ellipse fitting 과정을 거칩니다. 기본적으로 segmentation된 결과는 strokes' law와 young-laplace law가 가정하는 원은 커녕 타원도 아니기 때문에 segment된 결과와 가장 가까운 타원이라도 찾는 것이라고 보시면 될 것 같습니다.
이제 대충 타원의 크기와 aspect ratio, position을 구할 수 있는데 여기에 아까 구해둔 Reference ratio를 통해 일관된 값을 얻을 수 있도록 합니다.
Bubble Tracking
Bubble tracking 단계에서는 frame간에 bubble이 이동하는 궤적을 분석합니다. 이를 통해 bubble의 종단속도를 계산할 수 있게 됩니다. 그런데 현실적으로 bubble이 딱 하나만 존재하리라는 법은 없습니다. Bubble은 자기 마음대로 병 속에서 여기저기 존재할 수 있고 이러한 상황에서 bubble들 끼리 overlap되거나 하는 문제가 발생할 수 있습니다. 따라서 저자들은 해당 시스템을 위한 tracking algorithm을 제안합니다. 기본적으로 single bubble tracking이 있고 all unique bubbles tracking 2개로 나뉩니다.
Single bubble tracking의 경우 초기에 bubble 위치를 잡고 각각의 bubble들에 대해서 tracking을 수행합니다. Thresholding을 통해 single bubble을 찾아냅니다. 논문에서도 엄청 디테일 하게 다루지는 않고 해당 tracking을 반복하며 overlap 등이 발생하지 않은 unique bubble들을 찾습니다.
Prediction
자 이제 bubble feature들 까지 뽑았으니 이러한 feature들을 기반으로 분류 task 즉 prediction을 수행해야 합니다. 그런데 일반적인 machine learning이나 deep learning model의 경우 input의 shape이 일정한 경우를 가정하는 경우가 많습니다. 가령 CNN model들도 image의 resolution이 다른 경우 동작은 할지언정 학습에 사용된 resolution과 다르면 성능이 떨어지기도 하고, pooling과 같은 component에 의해서 연산이 제대로 이루어지지 못하는 경우도 더러 있습니다. 나아가 MLP나 random forest 같은 ML classifier들은 아예 다른 크기의 입력을 받지 못하는 경우도 있습니다.
그러나 해당 문제에 있어서는 조금 다릅니다. Bubble마다 bubble feature가 생성되는데, 기포가 반드시 동일한 개수가 발생하리라는 보장이 없습니다. 그렇다고 개수를 맞추기 위해 일부만 사용한다거나 하는 것은 해결책은 될 수 있겠지만 다른 문제들을 수반할지도 모릅니다. 또한 해당 시스템에서는 각 개체의 bubble들의 정보도 활용할뿐 아니라, 여러 개체에 대한 statistical feature도 활용합니다. 따라서 ML을 통해 분석하고자 하는 feature가 가지는 특성들이 다르니 이를 고려한 분류 모델이 필요하다는 겁니다.
이 문제를 해결하기 위해서 bubble feature를 활용하는 classifier와 statistical feature를 활용하는 classifier 두 개를 학습하여 이 둘을 ensemble하는 방식을 채택합니다. Model의 경우 AdaBoost를 사용하는데 이는 statistical classification meta-algorithm으로 각 feature들 간의 중요도 등을 잘 고려하여 좋은 성능을 낸다고 해석하고 있습니다.
Enhancing Bubble Generation
자 이제 14 페이지 짜리 논문에서 7 페이지에 처음으로 등장하는 Bubble Generation Enhancement와 관련된 것이고 꽤나 핵심적이고 중요한 부분인데 이렇게 논문의 중간에 숨어 있는 딱 한 paragraph 짜리 부분인데 아마 저자들도 해당 부분이 논문에서 가장 취약한 부분이라고 생각하셨을 수 있을 것 같다는 생각이 든다. 사실 본인도 이 논문을 읽던 도중 점도가 높은 꿀이면 모르겠지만 위스키나 기름 같이 점도가 낮은 액체의 경우 bubble을 충분히 생성되도록 하는 것이 굉장히 어려운 일이라고 생각을 했다. 실제로 해봐도 잘 생성이 안되었었다.
그런데 결국 이 논문에서는 bubble이 이쁘고 충분히 생성되는 것이 정말 가장 중요한 부분이니 이 문제를 해결할 필요가 있다. 그래서 작은 accessory를 추가했다... 위 그림을 보면 병 뚜껑에 볼펜 입구처럼 생긴 cap이 붙어있는데, 입구가 좁다보니 뒤집고 나서도 해당 공간에 남아 있는 공기들이 올라오며 공기가 예쁘게 뿅뿅 올라오게 되는거다.
"아니 저걸 설치하려면 병 뚜껑을 따야하잖아? 병 뚜껑 안 열고 분석하는게 목표라며!" 라고 할 수 있다. 그런데 한 번 바꿔서 생각해보면, 누군가 자기의 회사에서 만든 제품에 값싼 대체품을 넣고 팔다가 문제가 생겨서 논란이 되어서 주가가 떨어지는 것을 원하는 회사가 있을까? 결국 이 시스템은 단순히 사용자만 원하는 시스템이 아니라 제품을 만드는 회사에서도 필요로 하는 시스템이니까 회사에서 해당 cap을 달아주면 된다는 거다. 앞서 이야기한 marker의 경우도 회사에서 달아주면 된다. 이 시스템은 attack이 아니라 alternation attack을 detection하고 막는 것에 있으니 충분히 가능한 시나리오가 된다... 아마도 이걸 잘 풀어냈기 때문에 accept도 되고 best poster도 받은게 아닐까
Evaluation
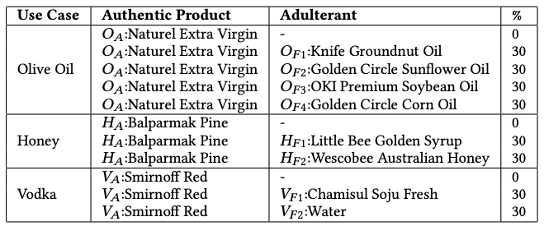
해당 시스템을 평가하기 위해서 올리브유, 꿀, 보드카 세 개의 case에 대해서 분석을 한다. Authentic product는 상대적으로 비싼 고급 제품들이고, Adulterant의 경우 값싼 제품들이다. 참이슬 소주 후레시가 눈에 띈다.
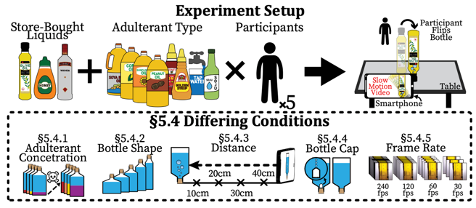
data collection의 경우 온도는 25도로 세팅을 하고 진행했다. 유체의 성질은 주변 온도에 영향을 받을 수 있으니 통제한 것이 당연하다. 병의 종류의 경우 11개, 병을 뒤집는 action은 2명의 여성 3명의 남성으로 이루어진 subject들이 있었고 각 8번씩 test를 했다고 합니다. 또한 카메라 기반 vision system이므로 light condition 또한 통제하였으며 여러가지 Adulterant 비율과 병의 모양, 카메라와의 거리, bottle cap의 유무, Frame rate 등의 변인들에 대해서 다양하게 실험을 진행했습니다.

Figure 7은 LiquidHash 시스템을 이용해서 분류한 성능과 참가자들에게 병을 개봉하는 것 이외에 시각적인 정보를 통해 주어진 병이 진짜인지 가품인지 구별하는 일을 시켰을 때의 성능으로 상대적으로 낮은 variance로 높은 accuracy를 얻는 것을 볼 수 있습니다. Figure 8의 경우 Accuracy Precision Recall으로 '모두 좋다'가 결론입니다.

위 결과는 모든 가품 조합들에 대한 성능으로 꽤나 좋은 성능을 보입니다. 점도가 높은 꿀의 경우 성능이 안정적으로 높은 편이고 Oil이나 Vodka는 상대적으로 조금 낮고 variance가 좀 있는 편인 것 같습니다.
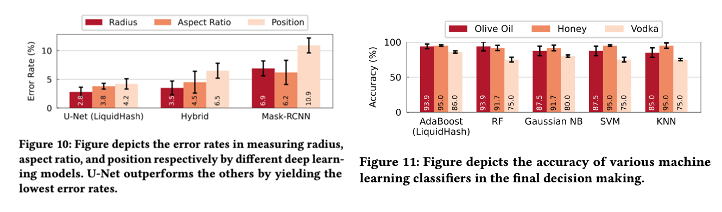
Figure 10과 11은 중간에 들어갔던 U-Net과 AdaBoost를 선정한 것에 대해서 정당성을 부여하는 실험으로 얘네가 제일 좋아서 얘네를 골랐다 정도로 봐주시면 될 것 같습니다.
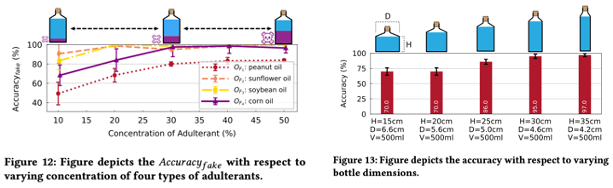
이번에는 adulterant 비율과 병의 모양에 따라서 성능이 어떻게 변하는지에 대한 것으로 당연히 섞이는 비율이 커지면 커질수록 성능이 올라가고 병이 위아래로 길어지면 성능이 좋아집니다. Bubble이 움직일 거리가 길어지니 꽤나 직관적으로 당연한 결과 같습니다.

15, 16은 각각 Frame rate와 거리에 대한 영향으로 당연히 Frame rate이 떨어지면 성능이 떨어지고 성능의 variance도 높아지며 거리가 너무 가깝거나 멀면 bubble의 크기나 움직인 거리에 대해서 정보를 제대로 추출하지 못해 성능이 떨어지고 variance도 커집니다. 20cm 정도가 꽤나 optimal한 거리인듯 합니다.

마지막은 cap의 유무에 따라 성능이 어떻게 바뀌느냐 하는 것입니다. 올리브유에 대해서 실험을 진행하였고, 꽤나 유의미한 성능차이가 있는 것으로 보입니다. 그래도 기본 cap으로도 81.3% 정도의 성능을 보이긴 했네요. 점도가 더 낮은 Vodka에서도 유사한 성능을 보였을지는 미지수입니다. 꽤나 의존성이 있긴 하지만, 암튼 cap을 달아서 해당 문제를 할 수 있으면 하는 게 좋지 않은가 하는 생각이 듭니다.
Conclusion
개인적으로 Technical하게 엄청 어려운 문제를 해결하는 논문이라고 생각했습니다. 물론 논문 작성을 위해 데이터셋 수집부터 모델 성능 평가와 데이터 분석의 과정이 쉬운 일은 아니지만 새로운 모델 구조를 제안하거나 가지고 있는 문제가 기존의 스킴들로 쉽게 해결할 수 있는 문제가 아니였기 때문이다. 다만 이러한 아이디어를 내고 이걸 이정도 수준으로 끌어올린 것에 엄청난 가산점을 줘야하는 연구라고 생각한다. 기본적으로 나는 이런 아이디어를 못내니까 말이다. 꽤나 기막힌 아이디어 아닌가?
추가적으로 연구를 한다면 뭐 사람이 맛의 차이로 이를 감지하는 것은 어느정도일지도 궁금하다. 해당 시스템이 어느정도까지 정확하게 분류가능하고 뭐 얼마나 섞였고 어떤 액체가 섞였는지도 알 수 있을지도 궁금하다
마지막으로 나도 술이랑 연관된 연구 주제를 잡아서 연구비로 참이슬 한 박스 사면 얼마나 좋을까 하는 상상을 했다...
끗!

