이전 게시글
FedBalancer 관련 세번째 게시글이다. 꽤나 이야기가 길어지고 있는데 다음부터는 적당히 요약해서 쓰는 방법을 고민해봐야겠다...
Loss Threshold Ratio & Deadline Ratio Control

논문의 Algorithm 3는 $ltr$ (loss threshold ration) 값과 $ddlr$ (deadline ratio) 값을 조정하는 방식을 설명한다.
FedBalancer에서는 적절히 현재 round $R$에서의 configuration (loss threshold와 deadline)을 활용하기 위해서 statistical utility ($U_{R}$)를 활용한다고 언급하고 있다. $U_{R}$는 $\frac{LSum_{R}}{L_{R}*ddl_{R}}$로 정의된다. $LSum_{R}$는 선별된 sample들에 대한 loss값의 합이고, $L_{R}$는 선별된 sample의 수이며 $ddl_{R}$은 round $R$에서 선정된 deadline이다. 잘 생각해보면 이는 loss의 평균을 deadline으로 나눈 값이다.
이렇게 계산된 $U_{R}$은 list $U$에 추가된다. 아마도 연산 시간을 줄이기 위함인 것으로 생각하는데, 매 round마다 값들을 조정하지 않고, $w$ round 마다 값들을 조정한다. 그리고 $ddlr$ 값과 $ltr$ 값을 키울지 말지를 결정하는데, 여기서는 $U_{R}$ 값들이 지난 $w$ round에서 어떻게 변경되었는지를 본다. 만약 감소했다면 $ltr$ 값은 $lss$ 값만큼 증가시키고, $ddlr$은 $dss$ 값만큼 감소시킨다. 만약 증가한 경우 $ltr$은 $lss$만큼 감소, $ddlr$은 $dss$만큼 증가시킨다.
이 전략을 다시 돌아보면, $U$ 값은 loss를 시간으로 나눈 값이니, 결국 시간당 발생한 loss의 값이된다. 따라서 이 값이 감소한다면 주어진 시간동안 loss가 적게 발생한 것이니 rough하게 생각해서 학습이 잘 되고 있다고 볼 수 있다는 것 같다. (필자가 이해하기론 그러한데 틀렸다면 지적해주시면 감사하겠다.) 반대의 경우는 주어진 시간동안 loss가 더 많이 발생한 것이니 학습이 제대로 되지 않았다고 보는 것이다. $ltr$은 학습이 잘 되고 있으면 증가시키고, $ddlr$은 학습이 잘 되고 있으면 감소시키는 값이다. FedBalancer가 가지는 목적을 생각할 때 Loss threshold는 점점 높여야 하는 값, deadline은 점점 줄여야 하는 값이므로 적절한 선정이라고 볼 수 있겠다.
Client Selection with Sample Selection
가장 초기의 FL에서는 random하게 client들의 subset을 뽑는 방식을 선택한다. 그런데 몇몇 연구에서는 어떤 client를 뽑느냐에 따라 global model의 수렴의 속도와 성능의 차이가 발생함을 밝혔다. 그러나 이러한 연구들에서는 sample selection이 존재하지 않는 상황을 가정하고 있어 sample을 dynamic하게 선별하는 FedBalancer에서는 다른 방식의 client selection이 필요하다는 것이 해당 subsection의 골자인 것 같다.
이 문제를 해결하기 위해 저자들은 새로운 statistical utility formulation을 제안한다.

사실 해당 공식은 Oort 논문에서 제시한 공식과 거의 유사한데, 여기서는 $OT^{i}$에 대해서만 보겠다고 scope를 좁힌 것이다. 이전 게시글에서 $OT$는 loss threshold를 넘긴 sample들이라고 이야기를 했다. 해당 수식에서 루트 바깥의 녀석을 루트 안으로 넣어 다시 쓰면, $\sqrt{|len(OT^{i})|\sum_{s\in OT^{i}}Loss(s)^{2}}$가 된다.
본인이 이쪽으로는 공부를 많이 하지 않아 해석을 하는 것이 조심스럽긴 하나, 결국 statistical utility가 높은 client에 priority를 주고 선정하는 것이 학습의 관점에서 도움이 된다는 것인데, loss threshold를 넘긴 sample이 많고, 그 sample들의 loss 값 자체도 큰 client는 아직 학습이 부족하다고 해석할 수 있는 것같다. 따라서 해당 값이 큰 client들을 한 번 더 학습에 참여할 확률을 높이는 것이 전체적인 학습의 관점에서 도움이 될 거라는 것 같다.
Adaptive Deadline Control
이제 FedBalancer의 사실상 마지막 부분이다. FedBalance의 성능은 학습에 가장 적절한 sample을 선별하고, 최대한 deadline은 tight하게 설정하여 올릴 수 있다. 앞서 이야기한 내용들은 모두 sample 선별과 관련된 것이라고 하면, 이제는 어떻게 deadline을 잡을 것인가 하는 것이다. 여기서 저자들은 deadline 설정을 위한 지표인 DDL-E (deadline efficiency)를 제안한다.
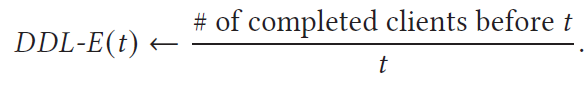
결국 시간 $t$가 흘렀을 때 학습을 끝낸 client의 수를 $t$로 나눈 것이다. 즉 시간당 끝난 client의 수가 된다. 직관적으로 생각해보면 학습이 시작되고 나서 client들이 학습을 끝내기 시작하면 DDL-E는 가파르게 증가했다가 어느정도 client들이 학습을 끝내면 거의 유리함수의 개형을 가지고 감소하게 될 것이다. 논문에는 FEMNIST와 Shakespeare dataset을 대상으로 해당 값을 plot한 figure가 있어 가지고 왔다.

너무 짧은 deadline은 global model에 참여하는 모델이 줄어들기 때문에, 너무 긴 deadline은 학습에 너무 시간이 오래걸리므로 time-to-accuracy가 떨어진다. 따라서 적절한 deadline을 설정해야 하고, 그 적절함의 기준은 DDL-E가 된다. 쉽게 말하면 해당 지표가 가장 높은 부분(붉은 원으로 표시된 부분)이 가장 효율적인 지점, 즉 시간당 학습이 끝난 client가 가장 많은 시점이라는 것이다. 저자들은 DDL-E의 distribution이 max value 인근에서 peak 형태를 보인다는 관찰을 통해 optimal deadline을 찾을 수 있겠다고 이야기 한다.

Algorithm 4는 deadline을 selection하는 알고리즘으로 DDL-E의 peak를 찾는 것과 이를 기반으로 Deadline을 selection을 하는 두 가지 선택지로 나뉘어져 있다. 우선 peak를 detection하는 알고리즘에는 client의 capability information이 사용되었는데, client $i$에 대해 DownLink speed ($DL^{i}$)와 UpLink speed ($UL^{i}$) 그리고 Batch Training Latency ($B^{i}$)를 사용한다. DownLink와 UpLink는 각각 client가 server와 통신을 하는 속도를 의미한다. 해당 정보들은 FL을 수행하기 이전에 이미 profiling이 되어 있다고 가정한다. 학습에 참여하는 client들에 대해서 학습시간과 통신시간을 모두 더 하여 평균적인 complete time을 예측하는 것이 기본이다.
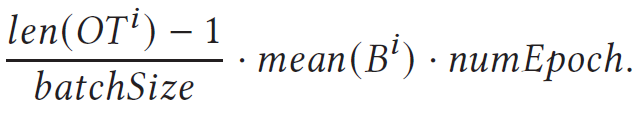
이 경우에 학습에 참여하는 client들이 가지고 있는 computing resource나 data의 개수가 다를 수 있으므로 학습 시간을 합리적으로 추론하기 위해서 위의 수식을 사용한다. 이 경우에 학습에 참여하는 모든 데이터의 수가 아니라 $OT$ data의 수를 기준으로 계산을 하는데 이러한 방식을 통해 sample seletion이 적용된 FedBalancer에서 최적의 deadline을 선정에 도움을 준다고 한다.
이렇게 계산한 DDL-E의 분포를 기반으로 가장 최적의 DDL-E point를 찾은 다음, 1 epoch을 학습한 경우 DDL-E가 가장 높은 $dl$과 $E$ epoch을 학습하는 상황에서 DDL-E가 가장 높은 $dh$에 대해서 $ddl_{R+1}$을 $dl+(dh-dl)*dllr$을 통해 새로운 deadline $ddl_{R+1}$을 선정한다. $ddlr$은 초기에 1.0으로 설정된 이후 $dss$ 값에 따라 점진적으로 줄여나간다.
기본적으로 FedBalancer는 학습 전략, 혹은 framework이므로 client가 모델을 학습하는 방식이나, server에서 어떤 방식을 global model을 찾는지 등은 충분히 바뀔 수 있는 부분이다. 따라서 해당 논문에서는 다른 FL method들과의 collaboration에 대해서도 언급 및 evalutation 하고 있다.
이를 통해 드디어 FedBalancer의 scheme에 대해서 쭉 다 훑었다. 중간중간 빼먹은 부분도 있지만 공부한 김에 최대한 꼼꼼하게 작성해두었다. 얼른 다음 게시글에 evaluation에 대해서 정리하고 이 논문 정리도 마무리 해야겠다.



